
Generating reports that show the effectiveness of tutoring is a challenge to all who coordinate tutorial programs. Though to demonstrate this definitively is almost impossible, there are ways that programs can collect data and generate reports to help show a correlation – if not causation – between tutoring received and improved academic performance.
Conventional wisdom would accept an obvious result of improved performance after receiving tutoring. However, most of us work at institutions with budget considerations where conventional wisdom is not enough. Our supervisors and senior administrators expect hard data that demonstrates the effectiveness of our programs and justifies their allocation of scarce resources. In this article, we will provide ideas on how to collect data and generate reports to highlight the usefulness of our services, justify stable funding, and guide us internally to allocate our resources to best serve students.
The Challenges of data collection and reporting
Some challenges to data collection seem obvious, while others vary by institution, administrative system, types of tutoring programs, staffing, and more. In regards to the latter (staffing), though most tutoring programs are required to generate some types of reports, few have appropriate staffing to achieve this goal. These programs are often forced to rely on university-wide data offices which have to accommodate all departments on campus, making it difficult to receive data assistance on a regular, timely basis.
While some programs collect data, it is done on paper and never entered into a computer, making it too laborious to generate sophisticated data reports. One can count “chicken scratches,” list the number of students who visited, and even note for which subjects they received tutoring, but making larger comparisons and correlations is impossible without being able to enter one’s data into database software and generate the desired reports.
Another challenge to data reporting was alluded to in the introduction. “Causation” (showing that tutoring directly causes higher grades) is nearly impossible to demonstrate. This is because a control group would be needed with the exact same variables as the main group studied: the same GPA, the same test scores, the same high school preparation, the same personal and economic profiles, ad infinitum. One can do this to some extent by using students with the same standardized test scores and similar GPAs, but this makes the groups much smaller and many unidentifiable variables and unique combinations of variables affect academic performance. Since having totally similar groups is unattainable, “correlation” is the best one can achieve. Furthermore, it is often only apparent correlation. Data can be collected to show that certain, specific students who received tutoring performed better than certain students who did not; however, that correlation is apparent and not actually proven. Consequently, we are often forced to depend on unreliable conventional wisdom to bridge the gap between the data we can collect and what we want to prove.
Attached is a report entitled “The Positive Effects of Tutoring on Retention.” It shows an apparent – and positive – correlation between tutoring and retention: students who received tutoring had a higher rate of retention than similar students who did not. In addition, it shows that the more hours of tutoring received, the higher the rate of retention. While further statistical analysis could be done on this data to show the small probability that this happened by chance, the consistency of those being tutored always having better retention is powerful evidence of the efficacy of tutoring.
It should be noted that we deliberately chose to investigate a correlation between tutoring and retention because our direct supervisor (the Dean of Undergraduate Studies) is in charge of retention and would find such data helpful. We could have chosen to compare tutoring to a lesser need to repeat courses, and we have done so in the past when our system (the California State University system) was concerned that too many students were repeating courses, thus slowing their progress to the degree. The point being made is that one must be selective in choosing what data to collect and assess how best to profile it. While one program may show higher GPAs in a certain class after tutoring, another program may want to show that more students pass a certain class with tutoring than without.
Below is a chart with simple statistical analysis to see if the apparent benefits
from tutoring occur by chance. Since we studied only Intermediate Algebra students,
the compared groups were similar in their mathematics skills. Data needed for
this study included how many visits the students made to the tutoring center,
the class they took and got tutored in, and the grades that all students who
took that course received. We included all students at the university who took
Intermediate Algebra, and indicated whether they passed or failed.
Our first step was to analyze the data as a contingency table. Doing a Chi-squared
analysis on this data gives a value of ![]() .
In a 2x2 table for
.
In a 2x2 table for ![]() the
the
![]() critical value is 6.63490.
This results in a 99% likelihood that the grades are not independent of whether
the student had tutoring. The students who were tutored had a significant difference
in their passing rate. It appears that their passing rate was higher. (For those
interested, there is another test – the Fisher Exact Test – that
can be used here. For the 2x2 table it gives us a value of
critical value is 6.63490.
This results in a 99% likelihood that the grades are not independent of whether
the student had tutoring. The students who were tutored had a significant difference
in their passing rate. It appears that their passing rate was higher. (For those
interested, there is another test – the Fisher Exact Test – that
can be used here. For the 2x2 table it gives us a value of ![]() ,
which would show a 99.9% probability that attending tutoring is responsible
for the difference in passing rates.)
,
which would show a 99.9% probability that attending tutoring is responsible
for the difference in passing rates.)
We have found that in order to obtain good statistics, one needs a large amount of data. Depending on the size of your program, it may take between five and fifteen years to collect enough data to make strong statistical statements. To help get large numbers for analysis, you should “bin” (put into groups or categories) your data into as few groups as possible. (You will note that in our contingency table we used only four groups for all students.)
Though the task of collecting data and preparing reports that demonstrate the
effectiveness of tutoring is, indeed, very challenging, we hope to encourage
others by providing the following suggestions:
- Invest in computer software in order to collect data directly into the computer.
- Keep documentation on how reports are created (who compiled the data, fields
used, etc.)
- Design the database system to correlate with the data that one’s supervisor
needs to support specific
programs.
More information on the subject is available through our web site: http://dcr.csusb.edu/LearningCenter/
Select “LC Data Reports” to see suggestions on how to design a database
collection system, examples of screens for sign-in computers, additional data
reports, and more. In addition, those interested in technical discussions of
contingency tables can access the following web sites:
http://www.physics.csbsju.edu/stats/contingency.html
http://www.tufts.edu/~gdallal/ctab.htm
http://en.wikipedia.org/wiki/Contingency_table
Questions or comments? Contact the authors at clinton@csusb.edu or swentwor@csusb.edu.
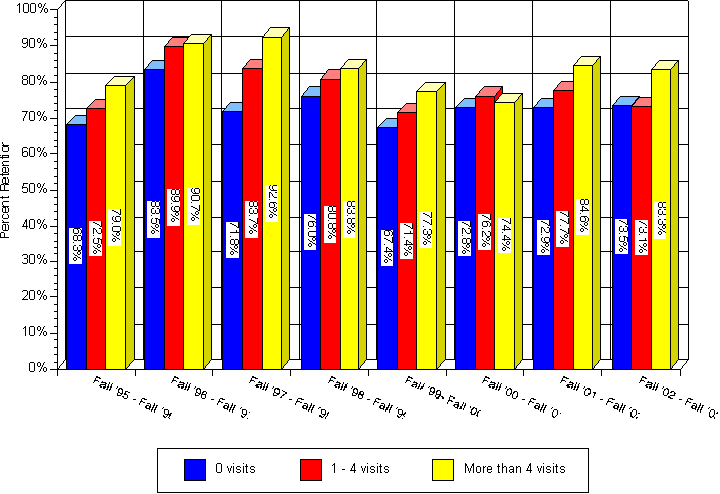
The chart indicates that students who received tutoring from the Learning Center have a higher rate of retention than those who did not receive tutoring. In addition, it indicates that the more tutoring received, the higher the retention rate.
Note: Retention in this report is measured from fall to fall for students receiving tutoring in the first fall. They are compared to those students who were taking the classes for which the Learning Center offered tutoring.
Fall 2000 was a low budget year (25% reduction). The reduction in tutoring
seems to have reduced our effectiveness. It is also interesting to note that
Fall 1997 was a high budget year (20% increase). This increase in tutoring seems
to have improved our effectiveness.
(Compiled by Stephen Wentworth, Learning Center ITC, April 5, 2006)